Knockout.js is a fantastic MVVM framework that handles observables, templating, styling, and more. It's easy to learn, but getting good performance out of it in larger apps can be difficult. Not to worry though, a few easy tweaks can make your app almost as responsive as a native app!
Understanding Dependencies
One of Knockout's most powerful features is its automatic dependency tracking. You can read the full, official documentation on it here, but the TL;DR is that when you declare a computed observable, the framework keeps track of all other observables (computed and otherwise) that the computed accesses. Whenever one of these dependencies changes value, all observables that depend on it automatically reevaluate their value. This method is very robust and works well, but carelessly-written computed observables can end up reevaluating themselves much more than necessary and dragging your app's performance down with it. Take the following code, for example:
::javascript
var currentTime = ko.observable(new Date());
setTimeout(function() {
currentTime(new Date());
}, 100);
var something = ko.computed(function() {
var result = someDifficultCalculation()
return 'LOG: [' + currentTime() + '] calculation result is ' + result;
}, this);
The intended use of something here is to run a calculation based on some user input and dump the result along with a timestamp to an output box. But since the computed observable accesses currentTime, which is updated ten times a second, the browser tab would be perpetually frozen as the JavaScript engine tries to run the difficult calculation over and over. Other than the obvious solution of simply reading the time with new Date() once the calculation finishes, the currentTime() call could be replaced with currentTime.peek(), which returns the value of the observable without marking it as a dependency. Another option would be to simply make currentTime a plain old JavaScript object rather than an observable, thus avoiding dependency tracking pitfalls altogether. Another way to reduce dependency headaches when using computed observables is...
Pure Computed Observables!
Added relatively recently to Knockout, pure computed observables are a faster, more predictable way to glue your UI together. A "pure function" is one that:
-
Is deterministic. If A and B are passed into a pure function as arguments and C is the result, passing in A and B should always return C, regardless of the values of any other variables in the program.
-
Has no side effects. That is, it shouldn't change the program's state in any way, or write to any variables outside of its function scope.
For example, Math.sin() is a pure function. The sine of a number never changes under any circumstances, and computing it doesn't affect that number's cosine, absolute value, or any other property. $([selector]).css([property], [value]), on the other hand, is not a pure function; running it changes the state of the DOM, which will affect the value returned by subsequent $([selector]).css([property]) calls. It's important to note that since we can't pass values directly into a computed observable, pure computed observables should be pure functions of whatever observables and variables they read from. Yes, that means that by definition, all of Knockout's computed observables are deterministic. So that first part doesn't really help us at all. But fear not, as the second property is extremely useful!
Why are they so great, you might ask? Well, since they have no side effects, there's no reason for Knockout to reevaluate them when one of their dependencies changes value and they have no subscribers. This allows UI elements that are not currently being displayed to stop updating and redrawing themselves, even when the data they draw from to render continues updating itself in the background. Since using computed observables in this way is very common, apps that have lots of views but only a few on-screen at a time stand to gain a lot from using pure functions!
"That's great", you might think, "I'm going to replace all the normal computed observables in my whole app! It's free performance, after all!" Slow down there, slugger, it's not that simple. While nothing is stopping you from writing pure computed observables that have side effects, doing so is a surefire way to add bugs to your app. Since they're not guaranteed to run when their dependencies are updated, incorrect pure computed observables may fail to update program state when using a normal computed would have worked fine.
We're Not Cavemen, We Have Technology
You can stare at your code all day, diagramming out every last dependency and converting everything you can to pure computed observables, but at the end of the day application response time is what you really care about. Happily, Chrome's developer tools are extremely powerful and can help you figure out why that simple button press is taking ten seconds to update a simple block of text!
Behold, the profiler view! This unassuming screen allows you to see exactly what your app's call stack looks like, millisecond by millisecond!
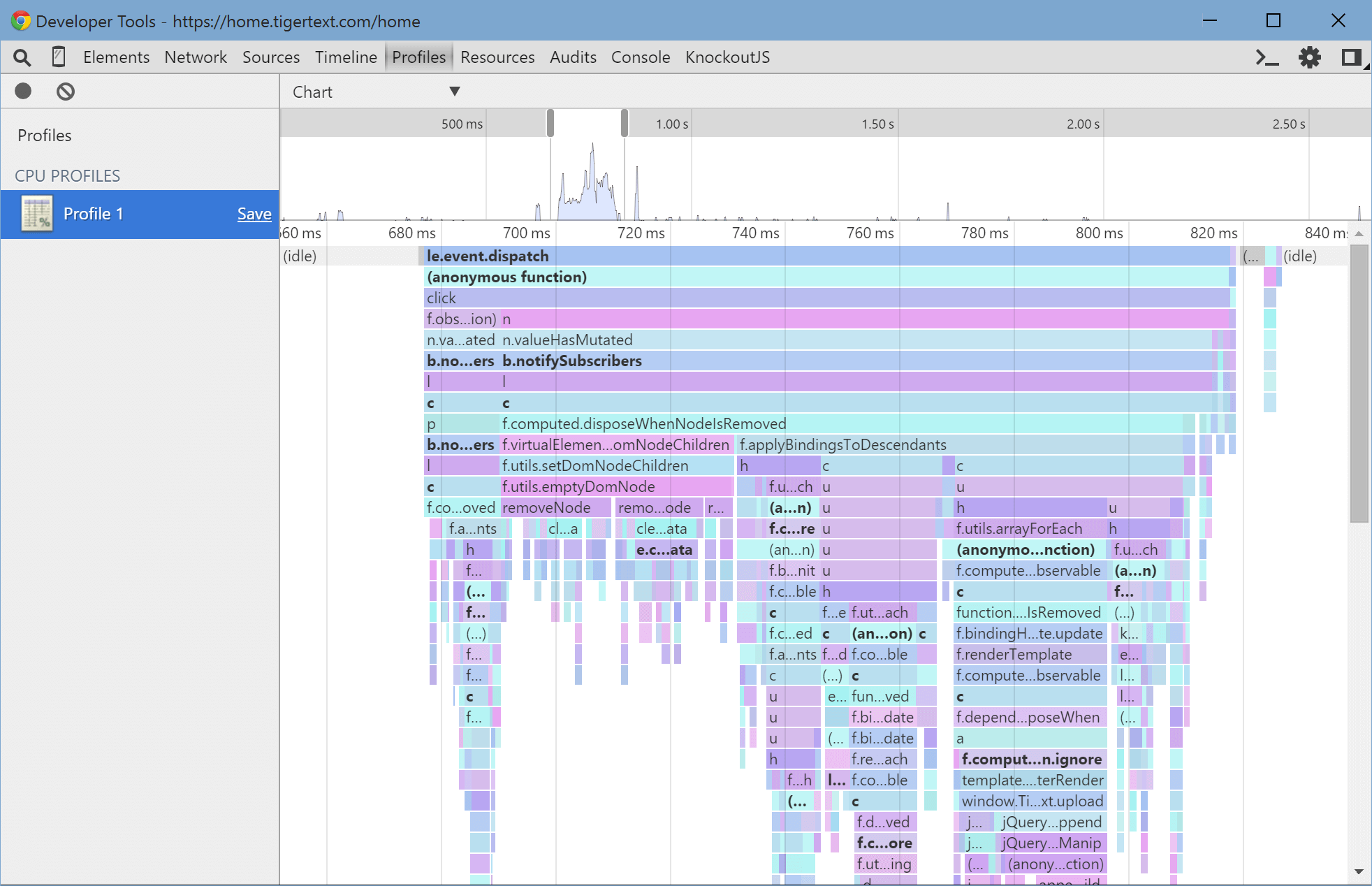
Start the profiler, do whatever you want, then stop it and change the view to the chart view with the dropdown at the top of the window. You can see exactly what functions are running, when, and how long they took. You can also click on each of those colorful little boxes to see where in the code that function is. The bottom-up view shows you which functions ran for the most time total, useful for deciding which functions to optimize first. You should be able to get a good idea of what Knockout's doing by looking at the function names on the chart, but sometimes you want to see exactly when something of interest is being executed. Unfortunately, console.timeStamp() only works in the Timeline view, so we'll have to be a little more clever to mark up the profiler chart. Instead, we need deep recursion (to make a big spike) and it has to take long enough for Chrome to realize it's happening. Copy/pasting something like this before and after a line of interest should generate an obvious shape in the resulting chart:
var mark = function(depth) { if(depth == 0) { var j = 0; for(var i = 0; i < 1000000; i++) j++; // log it so the loop doesn't get optimized out console.log(j); } else { mark(depth - 1) } }
It goes without saying that this is a horrible, hacky way to do things, but it's the only way at this time. Just be careful to remove this code as soon as you're done profiling your app.
Miscellaneous Binding Tips
I've recently come across two confusing bindings in TigerText that were causing some severe performance issues and have easy fixes. The first is the afterRender property of the foreach binding. At first glance it sounds like it's a function that Knockout runs after it finishes rendering every part of the foreach binding, when in reality it runs after each individual element renders. So this binding will run doSomething() things().length times:
<div data-bind="foreach: {data: things, afterRender: doSomething()}"> ... </div>
Needless to say, unless doSomething() is trivial, using the afterRender property will cause your app to chug like no other when rendering lists. Be very careful when using it. Consider subscribing to the underlying observable array instead, which will only result in one callback per change to the array. On a related note, make sure that when you add or remove multiple elements in an observable array, you do them all at once with splice or by setting the observable array to a new array object rather than doing a large number of push or pop calls. This causes subscribers to the array to only be notified of changes once rather than potentially hundreds.
The other binding issue concerns the if and visible bindings. On the surface, they're the same: if they evaluate to a truthy value, the element is displayed; if not, then it's hidden. The devil, of course, is in the details. When a visible binding evaluates to something falsy, the markup for the element is generated as usual, but a CSS rule of display: none is added to it. This results in a larger upfront cost, as the rest of that element's bindings as well as all child bindings are still evaluated, but displaying the element later is fast because all that has to happen is a quick browser repaint. visible, then is best used when you aren't concerned about a binding's memory usage, expect it to change between hidden and visible states often, and expect it to take a while to evaluate.
if, on the other hand, completely ignores all other bindings on the element if it evaluates to a falsy value. No markup is generated at all, and all child bindings are skipped as well. Bindings hidden by if consume no memory and take no time to generate, but every time the value of the binding changes from false to true, it and all child bindings must be reevaluated from scratch. It can be used for bindings that change between visible and hidden relatively infrequently, render quickly, or consume lots of memory.
That's all I've got. Go forth and optimize!